

 TEAM IM
TEAM IM
Customizing WebCenter Content Server: Part 1 - Content Server Architecture
By: Dwayne Parkinson - Solution Architect
By: Jon Chartrand - Director of Product Management
Perhaps the primary conceit when it comes to content management is this: context is king. When your content or records have context, it means they can be both cataloged and discovered with much greater ease. When we talk about context, that means metadata – or data describing data. When a document is placed into your content management system it’s important to know who it came from, who it belongs to, what the data within is regarding, and every other aspect of context that can be known, implied, or assumed. This allows the system to catalog the item appropriately and other users to search for and locate the item easily. The problem is that while context is king, entering metadata can be a royal pain – and bad metadata can ruin an otherwise good system. As we all know: garbage in – garbage out.
 TEAM IM’s been working in the content management space for over a decade so we’ve seen this issue arise repeatedly for our clients. Relying on end users for full, complete, and accurate metadata puts stress on them, slows down the contribution process, and can lead to human error or, even worse, human disinterest. So we set out to not only solve this problem but revolutionize how context is achieved for your content. We partnered with SmartLogic and combined the power of Oracle WebCenter Content with their extraordinary context classification software, Semaphore, to create a unified, smart solution.
TEAM IM’s been working in the content management space for over a decade so we’ve seen this issue arise repeatedly for our clients. Relying on end users for full, complete, and accurate metadata puts stress on them, slows down the contribution process, and can lead to human error or, even worse, human disinterest. So we set out to not only solve this problem but revolutionize how context is achieved for your content. We partnered with SmartLogic and combined the power of Oracle WebCenter Content with their extraordinary context classification software, Semaphore, to create a unified, smart solution.
This is Intelligent Content.
TEAM IM’s Intelligent Content solution alleviates the challenges and roadblocks of requiring users to navigate the metadata process by doing the work for them. This is started by the user simply saving their content to the WebCenter Content repository. The content can be contributed automatically by line-of-business systems or even ingested from network drives or cloud-based file systems. The Intelligent Content engine processes the stored material and leverages an information classification model, or “ontology”, rather than the traditional two-dimensional taxonomy. Intelligent Content drives the auto-classification process by opening each document at contribution time and parsing the content of the document. It is then able to automatically populate metadata based on the rules of the classification model. By automatically tagging your materials, it makes your content easily findable across what would have previously been multiple taxonomic pathways.
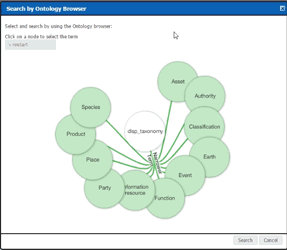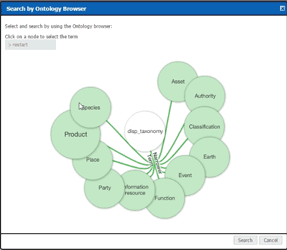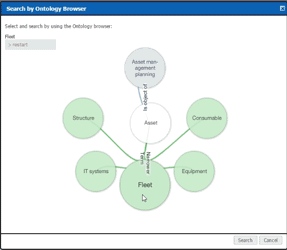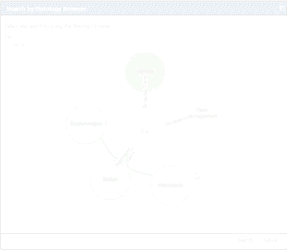
Perhaps an example can help here. Imagine an overview document that describes a land use project to build a park. The document may contain sections on project planning, soil samples, a work breakdown, price estimates, and more. In the old-school method the Project Manager checks the item into the repository and, on reflection, classifies the item as a Project Document type item with a subtype of Overview. This is helpful, but really doesn’t encompass the breadth and depth of what’s in the document. In the new-school method, Intelligent Content parses the text and applies predefined classifications; overview, soil samples, work breakdown, pricing... On and on. This means the item can be found by others who search based on what they’re looking for not necessarily solely on the structure of the item. The old-school method provides a single taxonomic pathway (Project Document > Overview). The new-school method enables a much more nuanced approach. When the Engineer looks for documents relating to soil samples, the item is returned. When the Construction Foreman looks for documents relating to Work Breakdown, the item is returned.
As I mentioned earlier, the ontology (AKA information classification model) is comprised of a set of terms and rules, which have the ability to be maintained as needed by the information or records management SME within your organization or through TEAM IM. By utilizing the information model on the search side of the equation, it allows the use of “semantically enhanced” search capabilities including a “search as you type” feature as well as the ability to browse through the model in an interactive graphical manner. Both methods create easier, faster, and more intelligent pathways for users to find the content they’re looking for in the system.
Help Your Contributors.
There’s a lot of room for human error when a document is manually classified. TEAM IM’s Intelligent Content solution saves the content contributor time and effort by automatically tagging newly stored content. This ensures that every time new content is stored in any department of your business, its classification will be consistent and no longer susceptible to the vagueries of human interpretation.
Help Your Users.
Will the end-user always know what key words to search for when looking for a specific document? The auto classification system makes finding your documents faster and easier than ever. What could potentially take hours to locate within a large system can now be found in a matter of seconds due to the unique ontology model utilized by Intelligent Content.
Help Your Business.
By changing the way your content is cataloged and managed, TEAM IM’s Intelligent Content solution is a bottom line contributor to the overall enhancement of your business.
While this sounds like a sales pitch – and I admit it kind of is – I want you to understand that we’re also incredibly excited about the results we’re already seeing from Intelligent Content; better classification, less human error, simpler contribution experience, and far faster and more accurate searching. This is the next step in the evolution of enterprise content management. If you’re interested in learning more, you can check out our YouTube video on this topic or email us directly with your questions.